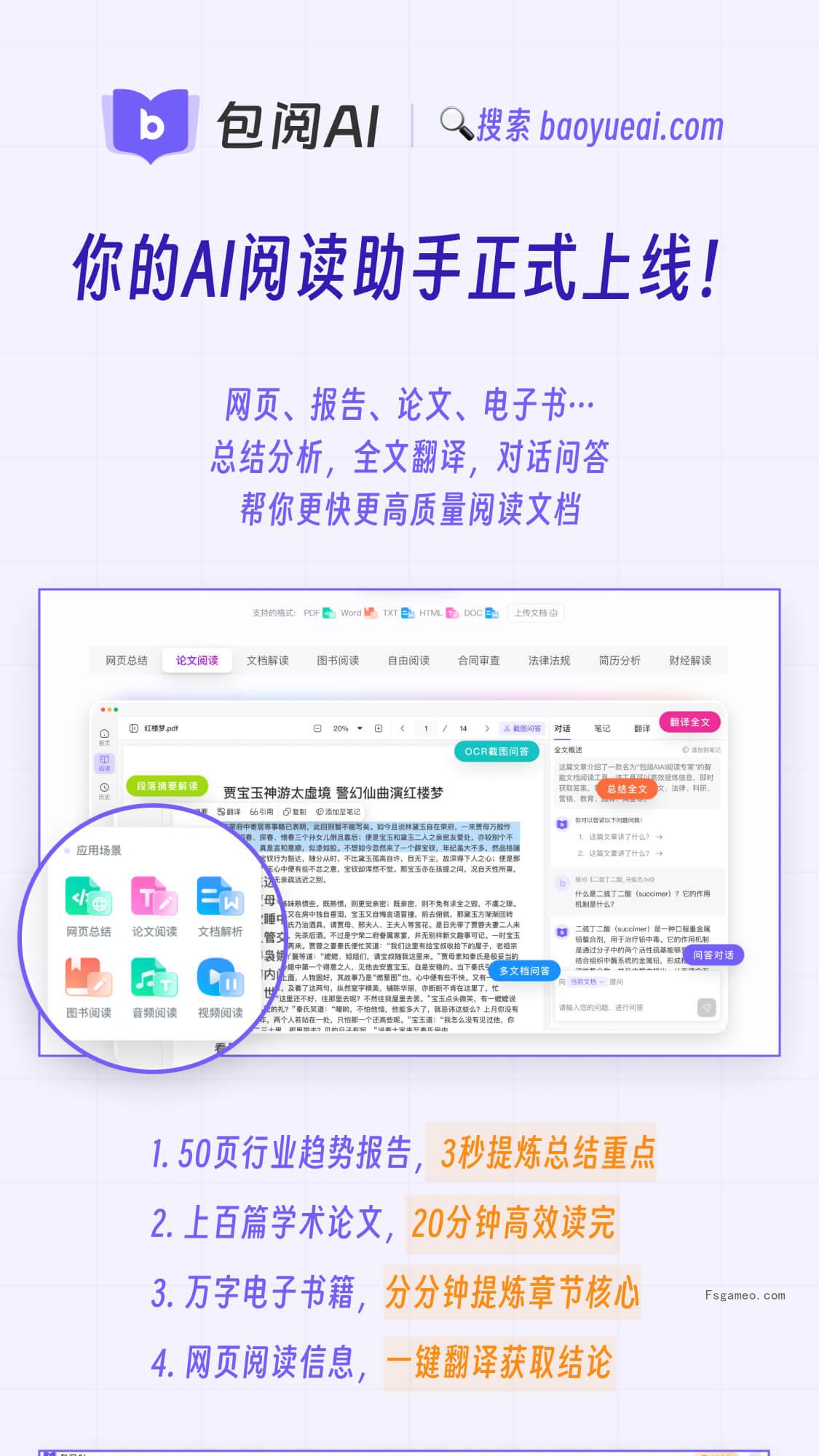
4月15日最新研究显示,美国哈佛医学院科研团队对20余款先进AI大型语言模型(LLM)的临床诊断效能进行了系统评估,测试对象涵盖ChatGPT、DeepSeek、Gemini及Claude等主流模型。实验数据显示,在仅依据患者初始症状和体征进行"鉴别诊断"时(即通过表征特征筛查潜在疾病),AI系统的误诊率高达80%。进一步研究发现,在整合患者补充提供的检验检查结果后,这些智能系统对"最终诊断"的判断失误率可降至约40%左右。研究负责人特别指出:"人工智能辅助诊断必须建立在完整医疗信息基础上才能保证准确性"并强调:"当前AI技术尚未达到无需医生介入即可独立完成临床决策的成熟阶段。"(第一财经)